A client of mine has the following configuration for many of their apps
- Azure API Management (Consumption plan) in front of an
- Azure Service Bus Topic and
- An Azure Function to process messages from the topic, with
- Azure Application Insights for monitoring everything and
- A static metric alert rule against the Application Insights instance, for Exceptions > 0 which
- Sends an email to an MS Teams email address which
- Posts an alert to MS Teams, whenever any exception occurs
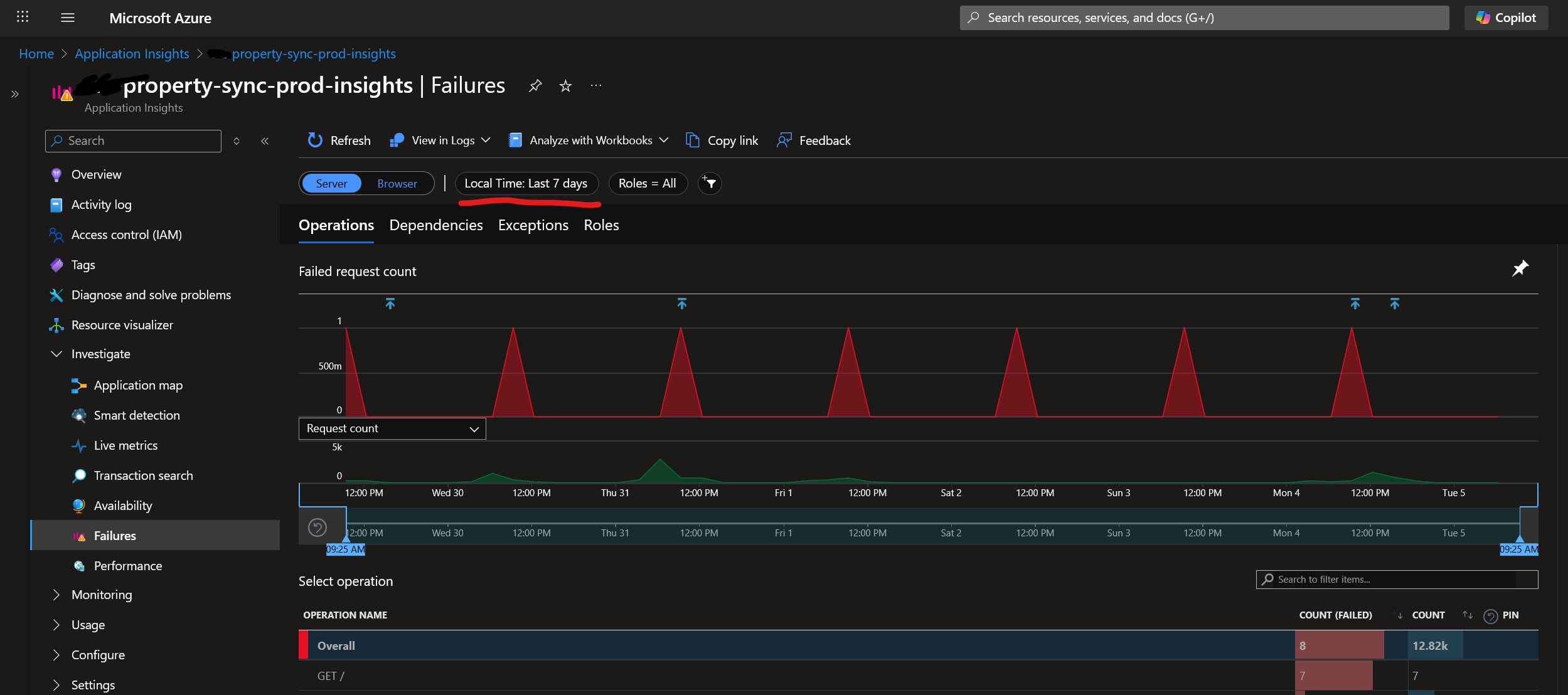
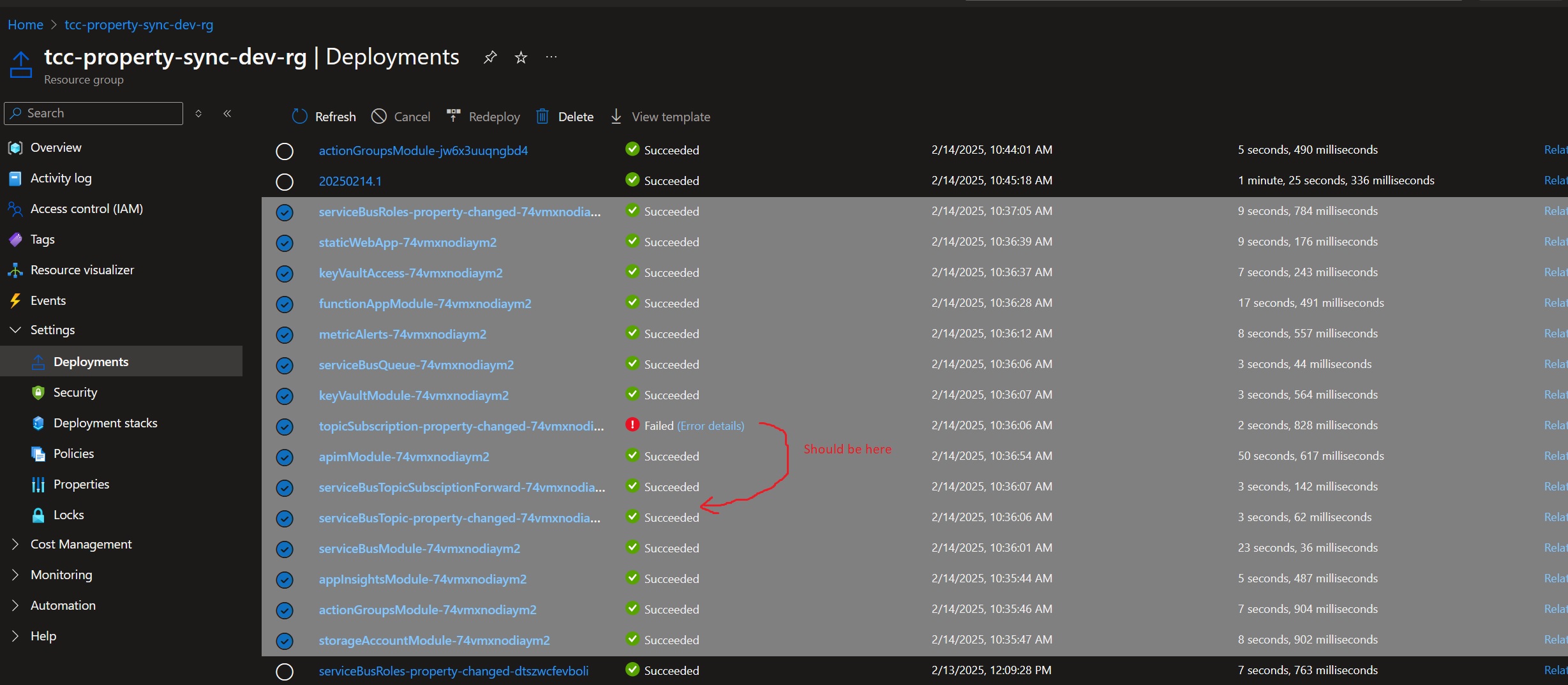
Every day at around the same time, something mysterious (which doesn’t belong to us) pings all of their Azure API Management instances at site root, i.e. GET /. We don’t know what it is, but I guess it’s something to do with Azure Monitoring or infrastructure, or a keep alive or something. Our APIM doesn’t have anything at site root /, so it returns a 404. This 404 is counted as an Exception which is logged as a regular Failure in Application Insights:
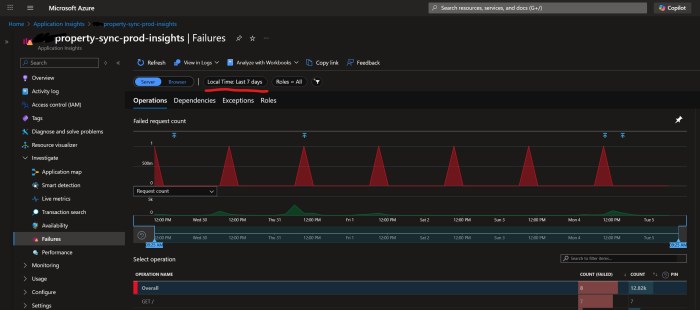
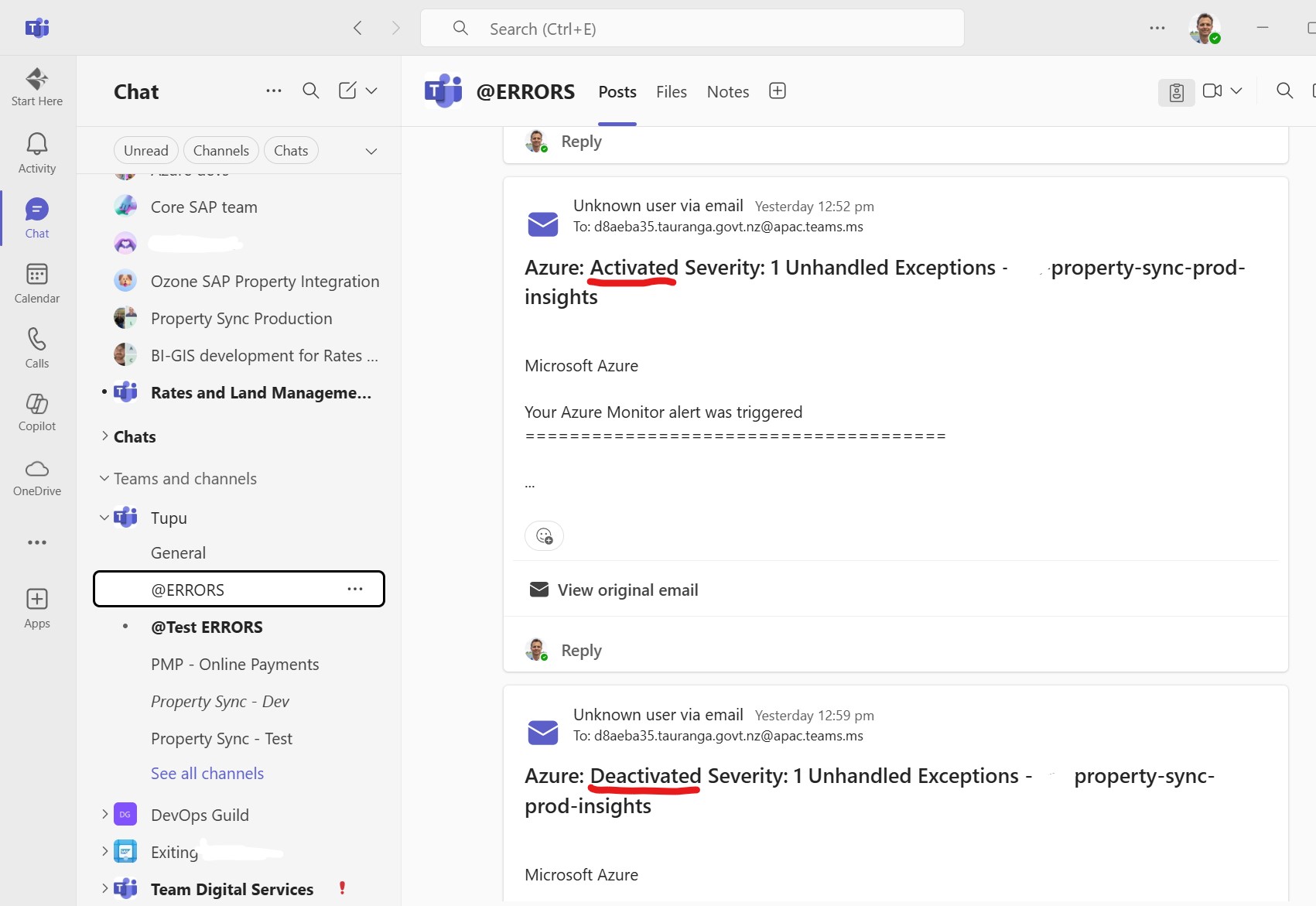
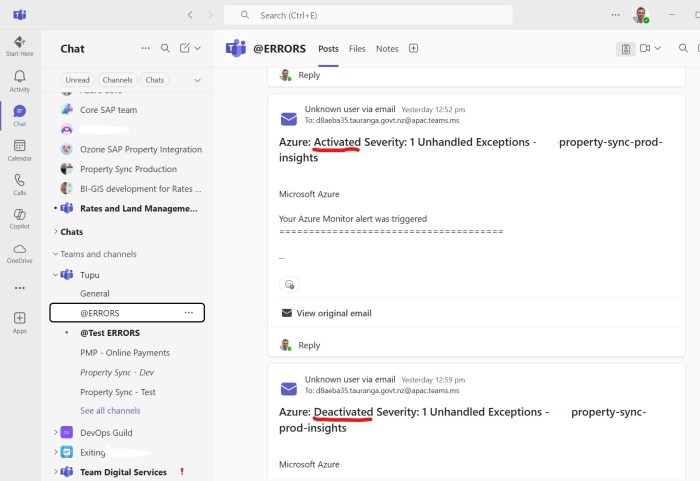
Which means every day at the same time we get false positive alerts (activated + deactivated) in our Teams channel:
The workaround is quite simple – add a “health check” endpoint at APIM’s site root to return a 200 instead of a 404. We can use APIM’s mock-response for this:
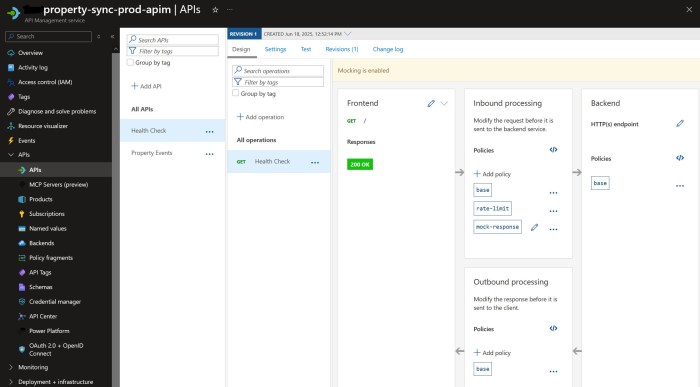
N.B. make sure the API’s URL scheme is both HTTP and HTTPS.
The inbound policy looks like this:
<policies>
<inbound>
<base />
<rate-limit calls="1000" renewal-period="60" />
<mock-response status-code="200" content-type="application/json" />
</inbound>
<backend>
<base />
</backend>
<outbound>
<base />
</outbound>
<on-error>
<base />
</on-error>
</policies>
And here’s a Bicep snippet to deploy it. Pro-tip: you can use ”’ to embed the XML:
resource healthPolicy 'Microsoft.ApiManagement/service/apis/operations/policies@2023-05-01-preview' = {
parent: healthOperation
name: 'policy'
properties: {
format: 'xml'
value: '''
<policies>
<inbound>
<base />
<rate-limit calls="1000" renewal-period="60" />
<mock-response status-code="200" content-type="application/json" />
</inbound>
<backend>
<base />
</backend>
<outbound>
<base />
</outbound>
<on-error>
<base />
</on-error>
</policies>
'''
}
}
Hopefully that helps someone.
Edit, a few days later:
Once we implemented the mock-response, that didn’t fix the problem of the alerts being fired. Whatever is calling us has a very short timeout, so our 404s became replaced with ClientConnectionFailure exceptions.
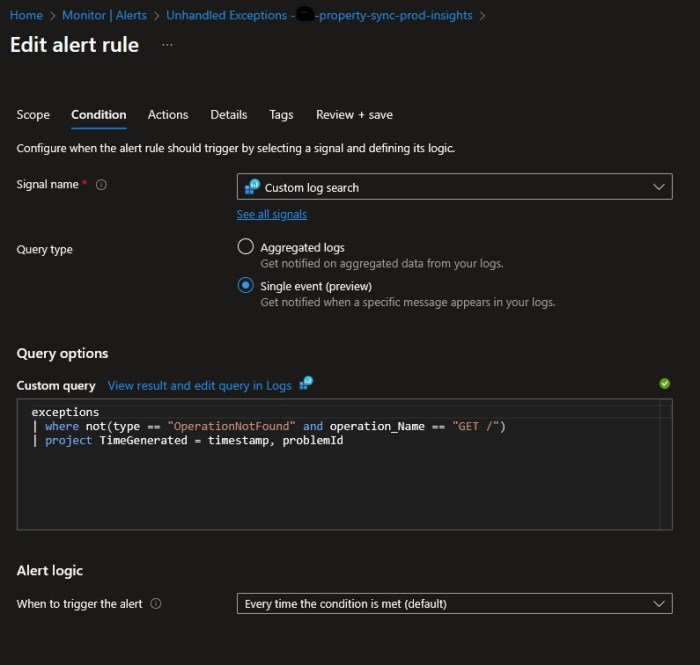
The workaround I settled on is to change our static metric alert on “Exceptions > 0” to a Custom Log search, and I explicitly exclude errors when calling the site root URL, with a custom query
exceptions
| where operation_Name != “GET /”
| project TimeGenerated = timestamp, problemId